CopyRight©2021 520资讯网 All Right Reserved
吉ICP备2023004123号-5
1月27日消息,国产GPU领域传来重大进展,天数智芯公司公布的四代架构路线图表明,其产品预计在明年可超越英伟达的Rubin架构。
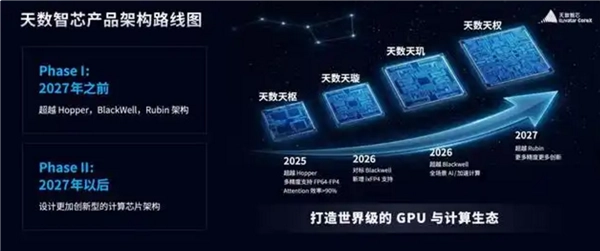
天数智芯AI与加速计算技术负责人单天逸公布的四代架构路线图显示:2025年,天数天枢架构将超越Hopper(H200系列);2026年,天数天璇架构对标Blackwell(B200),同年天数天玑架构超越Blackwell;2027年,天数天权架构超越Rubin;2027年之后,公司将转向突破性计算芯片架构设计。
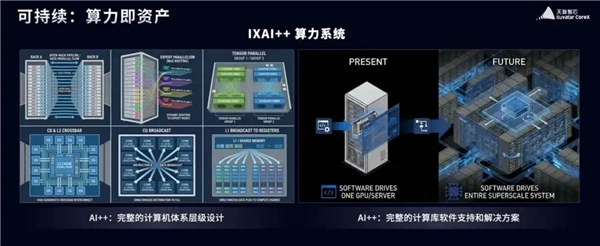
针对行业现存的能效比不高、创新能力不足、实际操作难度大等问题,单天逸指出,天数智芯通过优化设计为客户打造最优TCO(总体拥有成本),能够从容应对各类复杂的应用场景;可预期方面,依托精准的仿真模拟技术,客户在正式部署前就能提前预估性能情况,达成“所见即所得”的效果;可持续性上,则能无缝适配从传统算法到未来未知算法的迭代升级,保障设备的长期使用价值。

另外,单天逸还介绍了四代架构的关键细节:天数天枢架构,可支持从高精度科学计算到AI精度计算,AI芯片在执行注意力机制相关计算时,算力的实际有效利用效率能达到90%以上;天数天璇架构,新增加了ixFP4精度支持;天数天玑架构,实现了全场景AI与加速计算的覆盖;天数天权架构,则融入了更多精度支持与创新设计。
具体而言,针对天数天枢架构,单天逸详细阐述了多项核心技术创新的实现方式:TPC BroadCast(计算组广播机制)的设计借助上游数据广播来减少重复访存,从而在效果上提升带宽并降低功耗。
Instruction Co-Exec(多指令并行处理系统)的设计旨在实现对多种指令类型的并行处理,以此增强系统处理复杂任务的能力;而Dynamic Warp Scheduling(动态线程组调度系统)机制,能够借助动态调度的方式来避免资源争抢问题,进而提升计算资源的利用率。
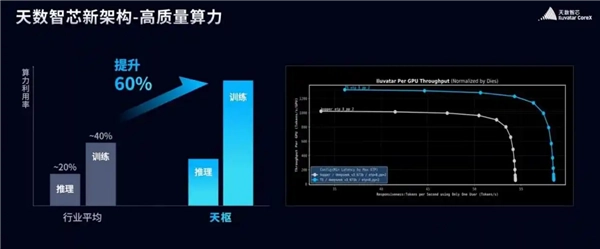
官方着重指出,这些创新举措使得天数天枢的运行效率相比当下行业平均水准提升了60%;依托这样的效率优势,在DeepSeek V3场景中,其实际性能表现平均要比Hopper架构高出约20%。
在发布会上,天数智芯董事长兼CEO盖鲁江提出,AI算力的发展需要依靠全栈自研来稳固生态基础,通过开放合作来构建新的发展模式,秉持长期主义共同打造产业未来;天数智芯希望与合作伙伴携手,让自主研发的通用GPU成果应用于各个行业,共同推动国产算力生态的蓬勃发展。
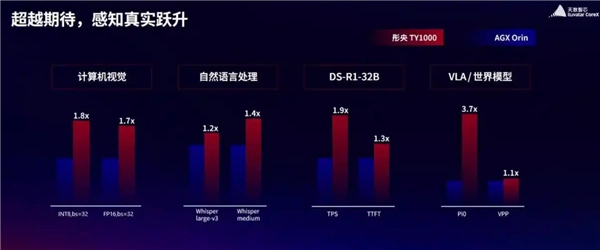
对于这样的重磅新品,中国工程院院士刘韵洁也来站台。
这位院士认为,AI算力既要保证数量充足,又要追求质量卓越,不仅要突破单个节点的性能限制,更要达成软硬件之间的高效协同;既需覆盖核心数据中心,也要延伸到边缘端的末梢环节,从而实现对全场景的赋能。同时,他也肯定了天数智芯多年来坚持自主创新、携手共建生态的稳健发展路径。